
Замечания об использовании кластера
Состояния сервера-члена кластера
Сервер кластера может находиться в следующих состояниях: AVAILABLE ("доступен"), BUSY ("занят"), RESTRICTED ("использование ограничено"), MAXUSERS ("превышен порог пользователей"), UNREACHABLE
("не функционирует") и INVALID. Состояние INVALID - переходное состояние, которое можно наблюдать в течение очень короткого отрезка времени, когда "отрабатывается" процесс вывода сервера из состава кластера.
Следующая таблица показывает, что будет происходить с запросом на доступ к базе данных на сервере кластера для клиентов Notes версий 3.х, 4.х и серверных задач Notes Replicator ("обычный" репликатор), Cluster
Replicator (внутрикластерный репликатор) и Mail Router (маршрутизатор почты). В таблице использованы следующие обозначения:
· Access granted - сервер выполняет запрос,
· Load balance - сервер генерирует событие load balance, а обратившиеся к нему станция или сервер предпринимают попытку перенаправить запрос,
· Failover - сервер генерирует событие failover, а обратившиеся к нему станция или сервер предпринимают попытку перенаправить запрос,
· No access - сервер отвергает запрос.
| Состояние | сервера | ||||||||||||
| Запрос от | Available | Busy | Restricted | MaxUsers | Unreachable | Invalid | |||||||
| Клиент R3 | Access granted | Access granted | Access denied | Access denied | No access | Access granted | |||||||
| Клиент R4 | Access granted | Load balance | Failover | Failover | Failover | Access granted | |||||||
| Клиент R4 (репликации) | Access granted | Access granted | Access granted | Access granted | Failover | Access granted | |||||||
| Notes Replicator | Access granted | Access granted | Access granted | Access granted | No access | Access granted | |||||||
| Cluster Replicator | Access granted | Access granted | Access granted | Access granted | No access | Access granted | |||||||
| Mail Router | Access granted | Access granted | Failover | Failover | Failover | Access granted |
Особенности внутрикластерного репликатора
Серверная задача Cluster Replicator осуществляет репликации "по событиям" изменения документов в базах текущего сервера, а не по расписанию. Эти события хранится в очереди событий в виртуальной памяти сервера. Если другой сервер-член кластера, на который должны быть переданы эти изменения, не функционирует, события "накапливаются" в очереди "исходного" сервера. При перезапуске "исходного" сервера "накопившиеся" в его очереди события будут утеряны. Так что не следует думать, что внутрикластерный репликатор всегда гарантирует "полную синхронность" реплик. Кроме того, выполняемые внутрикластерным репликатором изменения не протоколируются в истории репликаций баз. Поэтому, если синхронность реплик на серверах-членах кластера нарушилась, следует воспользоваться "обычным" репликатором. А чтобы вообще не задумываться о возможной несинхронности баз в кластере из-за рассмотренного свойства внутрикластерного репликатора, можно поддерживать внутри кластера и обычные репликации по расписанию. Конечно, такой подход несколько "груб", но зато надежен.
Кроме того, на сервере кластера может запускаться несколько внутрикластерных репликаторов. Если ресурсы компьютеров позволяют, в кластере из n серверов на каждом сервере-члене можно запускать до n-1 внутрикластерных репликаторов. При этом передача изменений с одного сервера-члена на остальные серверы будет происходить псевдо-одновременно, а не последовательно. В результате изменения должны передаваться в целом быстрее, чем при использовании одного внутрикластерного репликатора. Но практика богаче теории - в условиях недостатка оперативной памяти на серверах из-за усилившегося свопинга вы можете получить и обратный эффект.
Состояния баз Out of service и Pending delete
В документах базы данных CLDBDIR.NSF присутствуют поля, информация их которых отображается в колонках видов Out of service ("выводится из обслуживания")
и Pending delete ("ожидает удаления"). Не пытайтесь изменять значения этих полей в базе CLDBDIR.NSF - поля лишь отображают текущее состояние базы, но не могут его изменить.
Администратор выводит базу из обслуживания, когда ему необходимо получить к базе монопольный доступ, например, чтобы выполнить уплотнение базы. Все последующие обращения пользователей к базе, находящейся в состоянии Out of service, будут отвергаться и при возможности перенаправляться в реплику на других серверах кластера. В результате через некоторое время база будет "освобождена" пользователями. По своему смыслу это аналогично действию команды консоли Set Config "Server_Restricted=1", но не для всех баз на сервере, а только для конкретной базы. После того, как администратор проделает с базой необходимую работу, он обычно снова "вводит базу в обслуживание".
Администратор переводит базу в состояние Pending delete, когда ему необходимо убрать реплику этой базы с конкретного сервера-члена кластера. При этом обычно предполагается, что реплика этой базы имеется на других серверах кластера. Однако подлежащая удалению реплика может использоваться пользователями. Все последующие обращения пользователей к базе, находящейся в состоянии Pending delete, будут отвергаться и перенаправляться в реплику на других серверах кластера. В результате через некоторое время база будет "освобождена" пользователями. И только после того, как внутрикластерный репликатор "передаст" последние изменения из этой реплики в реплики на других серверах, данная реплика будет удалена.
Перевод баз данных в рассмотренные выше состояния осуществляется из окна Server Administration кнопкой Database Tools с последующим выбором "инструмента" Cluster Management.
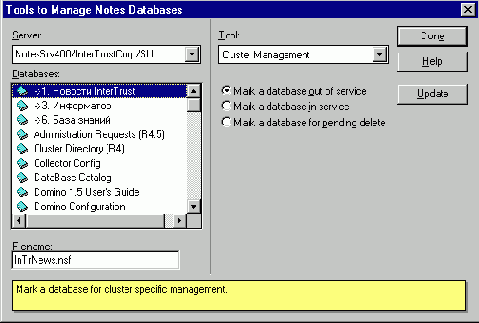
Рис. 10.12 Перевод баз в состояния Out of service, In service и Pending delete
Репликации с кластером
В командах консоли сервера для выполнения репликаций, а также в документах Connection для репликаций вместо имени сервера назначения может указываться имя кластера. При этом в репликации принимают участие не только реплики баз данных вызывавшего сервера и соответствующие реплики на том сервере-члене кластера, с которым было установлено соединение, но и соответствующие реплики на других серверах-членах кластера. Вызывающий сервер должен быть версии 4.5, наличие лицензии Lotus Domino Advanced Services для него не требуется. Аналогично можно поступать при репликациях между станцией и кластером.
Внутрикластерный обмен по отдельному сегменту локальной сети
Для того, чтобы внутрикластерный обмен серверов происходил по отдельному сегменту локальной сети, на компьютерах серверов должны быть установлены как минимум две сетевые карты с поддержкой необходимых стеков протоколов, а в файлах NOTES.INI
серверов должна присутствовать переменная Server_Cluster_Default_Port=<имя порта>. Здесь <имя порта>
- имя порта сервера Notes, связанного с протоколом и сетевой картой, подключенной к сегменту локальной сети, по которому должен происходить внутрикластерный обмен.